
La inteligencia artificial ya está entrando a operaciones reales: soporte, ventas, documentación interna, desarrollo de software, análisis de tickets, extracción de datos y automatización de tareas repetitivas.
El problema no es usar IA. El problema es usarla sin saber qué datos toca, quién puede pedirle acciones, qué sistemas consulta y cómo se revisan sus respuestas.
Una implementación útil empieza con una pregunta simple: qué proceso queremos mejorar sin perder control sobre la información.
El riesgo aparece antes de construir
Muchas empresas empiezan probando herramientas públicas con datos reales porque es rápido. Al principio parece inofensivo: copiar un correo, resumir un contrato, pegar una tabla, pedir una respuesta para un cliente o subir documentos internos.
Ese hábito puede crear riesgos difíciles de rastrear:
- datos sensibles compartidos sin autorización;
- información de clientes dentro de prompts sin control;
- documentos internos cargados en herramientas externas;
- respuestas generadas sin evidencia;
- usuarios con más permisos de los necesarios;
- costos crecientes por uso no medido;
- automatizaciones que ejecutan acciones sin revisión.
La IA debe tratarse como cualquier otra capacidad conectada a la operación: con alcance, permisos, monitoreo y responsables.
Clasifica datos antes de conectar IA
Antes de implementar un chatbot, asistente interno o flujo automatizado, define qué tipos de información existen y qué tan sensible es cada uno.
Una clasificación práctica puede empezar con cuatro grupos:
- Pública: información que ya puede mostrarse en el sitio, materiales comerciales o documentación pública.
- Interna: procedimientos, manuales, políticas, documentación técnica y conocimiento operativo que no debería salir sin control.
- Confidencial: datos de clientes, contratos, reportes, credenciales, información financiera, expedientes, tickets sensibles o diseños internos.
- Restringida: secretos, llaves, tokens, contraseñas, datos regulados o información que nunca debe exponerse a una herramienta general.
No necesitas un modelo perfecto desde el primer día. Necesitas una regla clara para decidir qué datos puede usar la IA y qué datos deben quedarse fuera.
Define el caso de uso con límites claros
Una iniciativa de IA falla cuando se define como “queremos usar IA”. Esa frase no dice nada sobre impacto, riesgo ni operación.
Conviene definir el caso de uso en términos concretos:
- qué tarea se quiere mejorar;
- quién la realiza hoy;
- qué datos necesita;
- qué salida debe producir;
- qué decisión sigue después;
- qué error sería aceptable y cuál no;
- quién revisa el resultado;
- qué sistemas se van a tocar.
Por ejemplo, “un asistente que responda preguntas sobre documentación interna” es más controlable que “un chatbot para toda la empresa”. También es más fácil de probar, medir y corregir.
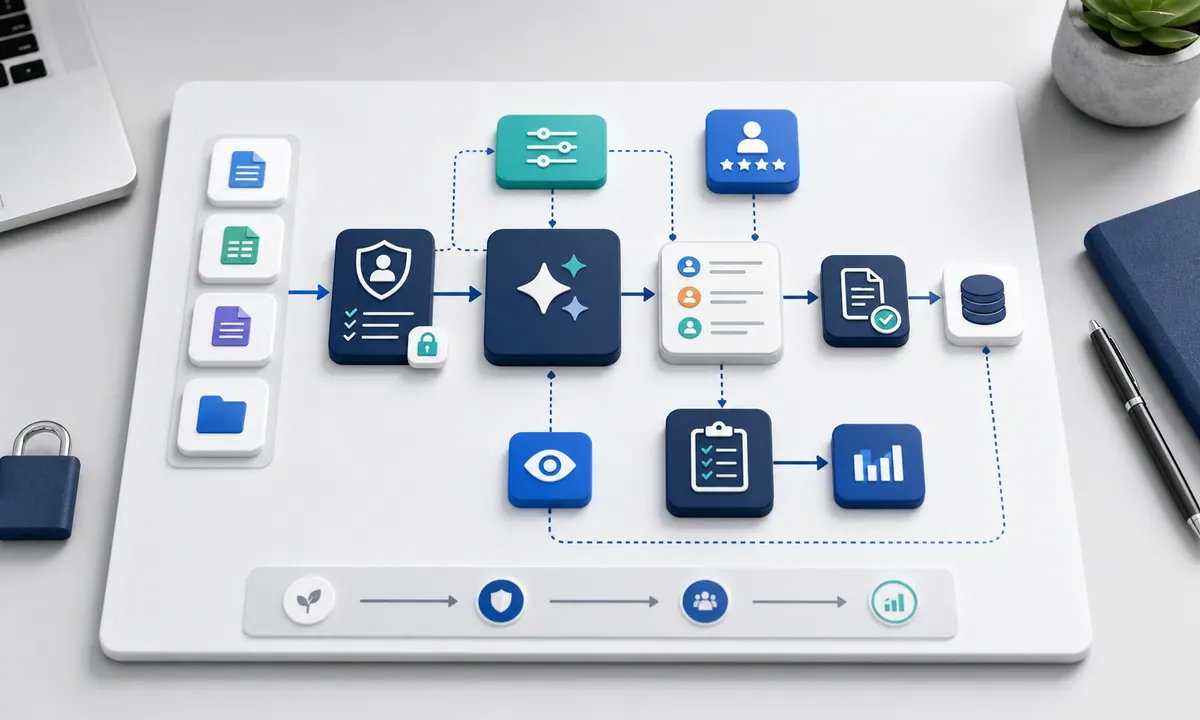
Usa permisos por rol, no acceso total
Una IA conectada a documentos o sistemas internos no debe ver todo por defecto. Si el usuario no puede acceder a cierta información en el sistema original, la IA tampoco debería poder usarla para responder.
Esto implica diseñar permisos por rol:
- ventas ve materiales comerciales y oportunidades autorizadas;
- soporte ve tickets asignados o categorías permitidas;
- administración ve reportes específicos;
- dirección ve indicadores consolidados;
- sistemas ve bitácoras, infraestructura y configuraciones según alcance.
El control de permisos debe vivir antes de la respuesta. No basta con pedirle al modelo que “no muestre datos sensibles”. La aplicación debe filtrar fuentes, validar identidad y limitar acciones desde la arquitectura.
Reduce respuestas inventadas con fuentes y evidencia
Los modelos pueden generar respuestas convincentes aunque no tengan evidencia suficiente. En una empresa, eso puede afectar clientes, decisiones internas o soporte técnico.
Para reducir ese riesgo:
- limita las fuentes que puede consultar cada asistente;
- muestra de dónde salió la información cuando sea posible;
- permite que responda “no tengo información suficiente”;
- separa conocimiento público de conocimiento interno;
- revisa conversaciones reales para ajustar límites;
- mide errores frecuentes antes de escalar.
Un asistente empresarial no tiene que contestarlo todo. Tiene que contestar bien lo que está dentro de su alcance y escalar lo demás.
Mantén revisión humana donde el impacto sea alto
Automatizar no significa quitar criterio. En muchos flujos, la IA puede preparar una respuesta, clasificar un ticket, extraer datos o sugerir una acción, pero una persona debe aprobar antes de ejecutar.
Mantén revisión humana cuando el resultado pueda:
- enviar información a un cliente;
- modificar datos en un sistema;
- bloquear una cuenta;
- cambiar permisos;
- generar una cotización;
- cerrar un ticket crítico;
- mover información sensible;
- afectar disponibilidad.
La revisión humana también ayuda a entrenar el proceso. Si el equipo corrige la salida, documenta el error y ajusta reglas, la solución mejora sin improvisar.
Registra actividad y mide uso
Una solución de IA en producción necesita trazabilidad. Sin registros, no puedes saber qué se preguntó, qué fuentes se consultaron, qué respuesta se generó, qué usuario actuó o cuánto costó el flujo.
Como mínimo, registra:
- usuario o sistema que hizo la solicitud;
- fecha y contexto del evento;
- fuentes consultadas;
- salida generada;
- acciones ejecutadas;
- errores o escalamiento;
- consumo aproximado;
- aprobaciones realizadas.
Estos registros no deben convertirse en otra fuente de exposición. También necesitan retención, acceso controlado y manejo cuidadoso de datos sensibles.
Empieza con una prueba piloto segura
Una buena prueba piloto no intenta resolver toda la empresa. Busca validar un flujo acotado con datos controlados.
Un piloto razonable puede seguir esta ruta:
- Elegir un proceso repetitivo y de bajo riesgo.
- Definir fuentes permitidas.
- Crear permisos por rol.
- Probar con usuarios internos.
- Medir errores, utilidad y tiempos.
- Ajustar límites y mensajes de escalamiento.
- Documentar costos, riesgos y próximos pasos.
El objetivo no es demostrar que la IA “puede hacer algo”. Es demostrar si puede mejorar un proceso específico sin romper seguridad, calidad ni operación.
Riesgos comunes en IA empresarial
La mayoría de los problemas no viene del modelo en sí, sino de cómo se integra.
Errores frecuentes:
- conectar IA a demasiadas fuentes desde el inicio;
- usar documentos desactualizados;
- no separar ambientes de prueba y producción;
- permitir prompts con datos sensibles sin filtro;
- no definir quién es dueño del flujo;
- no medir costo por usuario o proceso;
- no probar casos de abuso;
- no tener plan cuando la IA responde mal.
Guías como el AI Risk Management Framework de NIST y el OWASP Top 10 for LLM Applications pueden ayudar a ordenar riesgos, pero cada empresa debe aterrizarlos a sus datos, procesos y responsabilidades.
Cuándo conviene una integración a la medida
Las herramientas listas para usar pueden servir para pruebas generales, pero una integración a la medida suele convenir cuando la IA debe:
- respetar permisos internos;
- consultar documentos privados;
- conectarse a CRM, ERP, mesa de ayuda o aplicaciones propias;
- ejecutar acciones con aprobación;
- registrar evidencia;
- medir costos por flujo;
- operar con reglas específicas del negocio.
En esos casos, la IA no debe quedar como una herramienta aislada. Debe integrarse al software y a la operación donde ya existen usuarios, datos, permisos y procesos.
Enlaces internos útiles
- Política interna de uso de IA
- Checklist antes de usar IA con datos sensibles
- Conectar IA a documentos sin filtrar datos
- Inteligencia artificial para empresas
- Automatización con IA
- Chatbots con IA para empresas
- Integración de IA en software
- Ciberseguridad
La IA empresarial no se implementa bien por novedad. Se implementa bien cuando mejora un proceso real, usa datos correctos, respeta permisos y deja evidencia suficiente para operar con confianza.